Architecture
This document explains the concrete architecture and deployment of Observatorium within a single cluster and scaled out to multiple clusters.
TBD.
Regional cluster
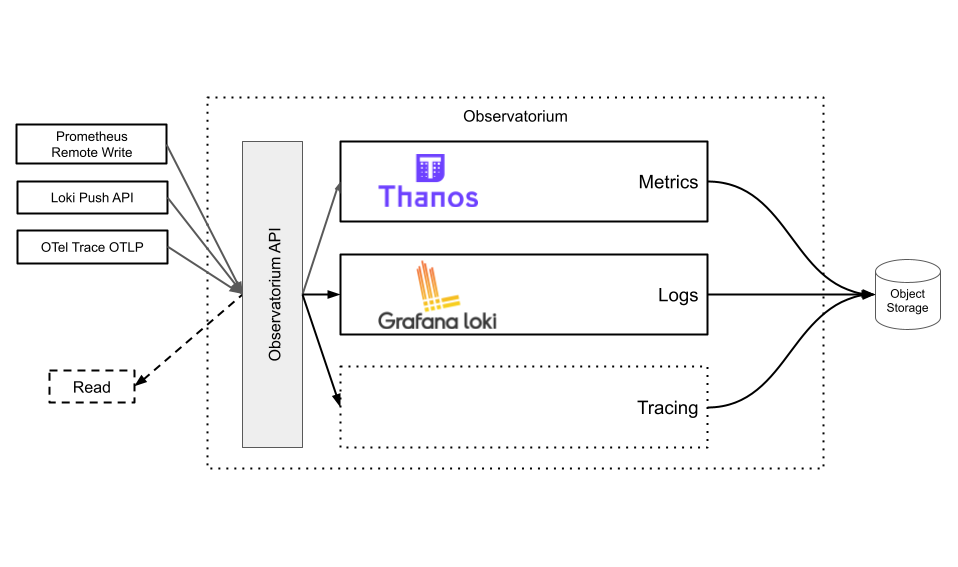
Observatorium supports writing and reading metrics. Writing is done via the Prometheus remote-write protocol. Regional clusters make use of regional object storage for data locality when querying as well as free network bandwidth.
The Observatorium API load balances write requests to one of the many instances of the Thanos Receive component. This component is deployed across multiple availability zones and replicates every request 3 times. The Thanos Receive component handles the hot inserts and produces immutable blocks of data every 2 hours. These 2 hour blocks are then uploaded to a regional Amazon S3 bucket.

When reading, a user accesses the Observatorium API, which exposes the Prometheus Query API using the Thanos Query component. The Thanos Query component fans out to both the Thanos Receive instances, for real time data, as well as the Thanos Store component, which reads and caches historic data from the regional Amazon S3 bucket.

Multi-cluster
In order to allow any cluster to make use of regional clusters to get the above described benefits, multiple clusters have to be deployed. When writing and reading Geo DNS determines which Observatorium endpoint is used. Internally the Observatorium components perform cross cluster communication, should data be necessary to be read from the other regional clusters. If data governance allows, then for latency reasons the regional storage can optionally be replicated to other regions.
